Collection and analysis of Twitter data
Twitter analysis in this report is based on 4.8 million tweets collected from March 8 to April 27, 2023. This process involved collecting batches of 3,000 new tweets every 30 minutes over the duration of the collection period using the Twitter Streaming API. This resulted in a sample of tweets created at different times and days over a number of weeks.
We regularly monitored the status of those tweets starting March 15 and ending June 15, 2023. Each day during the monitoring period, we looked up all collected tweets using the Twitter Search API. We collected the most recent engagement metrics for those tweets, as well as a status code indicating whether each tweet was still publicly available on the site or not.
Tweets were classified as unavailable if they returned a status code of “Not Found” (indicating the tweet itself had been deleted) or “Authorization Error” (indicating it was inaccessible because the account itself had been deleted or made private by the user or suspended by Twitter itself). Because we monitored the status of all collected tweets over the duration of the monitoring period, we were able to identify tweets that became visible again after previously being unavailable.
In addition to examining attrition rates using the full sample of 4.8 million tweets, we selected tweets from a random sample of 100,000 users, resulting in a sample of 148,494 tweets from our original collection, and gathered detailed information about those tweets and the users who posted them. These included details such as the language the tweet was written in; whether the bio field or profile picture of the account had been updated from the site defaults; the age of the account; and whether the account is verified. This subsample is used in the analysis of what types of tweets tend to be removed from the site.
Data collection for World Wide Web websites, government websites and news websites
To examine attrition on the broader internet, we collected three samples of web crawl data from Common Crawl, a nonprofit organization that collects and maintains a large web archive. This data has been collected monthly starting in 2008. We used this archive to create a historical sample of URLs from the broader internet dating back to 2013, as well as contemporaneous snapshots of pages from government entities and news websites.
Sample of URLs from the broader internet
This analysis is based on random samples of URLs from crawls conducted from 2013 to 2023, using year as a stratifying variable. We used the March/April crawl where possible and the closest available date range for years in which a March/April crawl was not conducted. This resulted in a full sample of 1 million pages – approximately 91,000 pages each year from 2013 to 2023 – that were known to have existed at the time they were collected by Common Crawl.
We then looked at whether these pages were still available in fall 2023 using the procedure described below. These checks were performed in several stages, running Oct. 12-Nov. 6, 2023.
Sample of government website URLs
This analysis is based on a random sample of 500,000 pages with a .gov domain, stratified by domain and level of government. We collected these pages from the Common Crawl MAIN-2023-14 crawl conducted March/April 2023.
Each page was assigned to a level of government (Federal – Executive; State; City; County; Federal – Legislative; Federal – Judicial; Tribal; Independent Intrastate; and Interstate) using https://get.gov, the official administrator for the .gov top-level domain. We retrieved the dataset used for this analysis Aug. 22, 2023.
This resulted in a sample with the following breakdown of domains and levels of government:
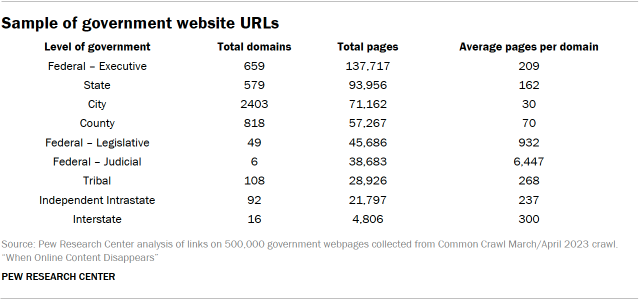
For each of the 500,000 pages collected, we selected a random sample of 10% of all links (internal as well as external) found on that page. This resulted in a total of 4,179,313 links. We then looked at whether the pages these links point to were still available.
Sample of news website URLs
The analysis of news websites is based on a list of 2,063 domains categorized as “News/Information” by the measurement and audience metrics company comScore. We divided these domains into quintiles based on comScore site traffic for Q4 2022 and sampled 500,000 total pages from these domains using site traffic quintiles as a stratifying variable.
This resulted in a sample with the following breakdown of domains:
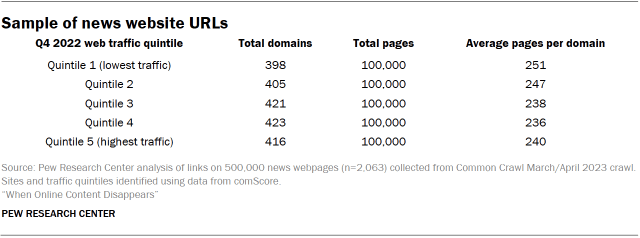
We selected a 50% simple random sample of all the 7,089,514 links that appeared on these pages, excluding any internal links (those that point within the same host domain). We then looked at whether the pages these links point to were still available.
Data collection for Wikipedia source links
We sampled 50,000 pages from the list of all titles in the English Wikipedia May 20, 2023, snapshot on Sept. 20, 2023. As some pages have multiple titles in the list of all titles, but refer to the same page (for instance, “UK” and “United Kingdom”), we followed redirects to eliminate duplicate titles for the same page. Between the snapshot and our collection, 50 pages were removed; our analysis is based on the remaining 49,950 pages.
Our analysis evaluated all external links (that is, links pointing to non-Wikipedia domains) from the “References” section of all the pages in the sample as of Oct. 10-11, 2023, using the same definition of link and procedure described above.
Evaluating the status of pages and links
We categorized links as alive or dead using the response code from the page. A page was classified as inaccessible if the domain was not available in a DNS server or if the server returned one of the following error codes indicating the content was not available:
- 204 No Content
- 400 Bad Request
- 404 Not Found
- 410 Gone
- 500 Internal Server Error
- 501 Not Implemented
- 502 Bad Gateway
- 503 Service Unavailable
- 523 Origin Is Unreachable
Pages were considered accessible in all other cases – including ambiguous situations in which we could not guarantee that the content exists, like soft 404 pages or timeouts not caused by the DNS.
We evaluated links in four rounds. In the first round (Oct. 12 to Oct. 15), we evaluated whether links were functional by following them using the requests library in Python, allowing for pages to timeout after one second. In this round, we recorded the initial status code and final status code after redirects, if applicable.
For the pages that did not return a 200 OK status code, we did a second round of evaluations (Oct. 16 to Oct. 17) in which we collected the status code using randomized browser headers from the library fake_headers.
A third round (Oct. 27 to Oct. 28) rechecked pages that did not successfully resolve to any status code and for pages that returned a 429 (“Too many requests”) status code, with an additional timeout of three seconds.
In the final round (Nov. 6), we looked up the pages that did not return any result in a DNS server using the dnspython module in Python allowing for a three-second timeout.
Definition of links
We identified hyperlinks from the HTML code of the websites by looking at all <a> tags that included a href attribute. We limited our attention to hyperlinks that used the HTTP or HTTPS protocol. Pages frequently use relative links that do not include the specification of the scheme and domain of the site in the definition. In those cases, we restricted our attention to those that referred to subdomains or paths (i.e., that started with a backslash /) and discarded hyperlinks defined by anchors (i.e., that started with a pound sign #).
Whenever a page used a relative link, we tried reconstructing the absolute URL by prepending the domain information. In our analyses, these reconstructed URL were treated as any other URL during our analyses.






