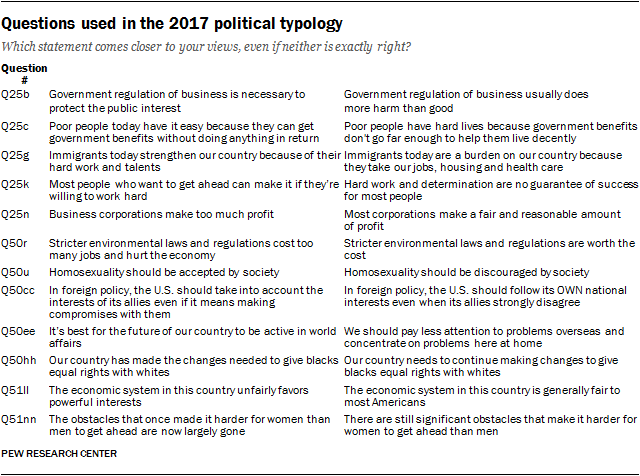
The 2017 political typology divides the public into eight politically engaged groups, along with an ninth group of less engaged Bystanders. The assignment of individuals to one of the eight core typology groups is based on their responses to 12 questions about social and political values and their party affiliation.
The questions used in the typology construction are in a balanced alternative format where respondents choose which of two statements most closely reflects their own views (see below). Items included in the typology construction measure a variety of dimensions of political values and are used to group people in multi-dimensional political space. Many of these values are similar to those used in past typology studies.
The typology groups are created using a statistical procedure that uses respondents’ scores on all 12 items and their partisanship (including leaning) to sort them into relatively homogeneous groups. The specific statistical technique model used to calculate group membership was latent class analysis (LCA). The items selected for inclusion in the LCA model were chosen based on extensive testing to find the model that fit the data best and produced groups that were substantively meaningful. Prior Pew Research Center typologies used a closely related method, cluster analysis via the k-means algorithm, to identify groups.
LCA and similar methods are not an exact process. Different solutions are possible using the same data depending on model specifications and even the order in which respondents are sorted. To address the sensitivity of cluster analysis to the order in which cases are entered, each model was run several thousand times. The results were combined using Stephens’ label switching algorithm for dealing with the arbitrary ordering of the groups in different solutions. Models with different numbers of groups were examined, and the results evaluated for their effectiveness in producing cohesive groups that were sufficiently distinct from one another, large enough in size to be analytically practical and substantively meaningful. All models were run using the statistical software R 3.4.0, and we made use of the “poLCA” and “mcclust” packages.
While each model differed somewhat from the others, all of them shared certain key features. The final model selected to produce the political typology was judged to be strong from a statistical point of view, most persuasive from a substantive point of view, and was representative of the general patterns seen across the various models run.
As in past typologies, a measure of political attentiveness and voting participation was used to extract the “Bystander” group, people who are largely not engaged or involved in politics, before the remaining respondents were sorted into groups. Bystanders are defined as those who are: 1) Not registered to vote; 2) Say they seldom or never vote; and 3) Do not follow government and public affairs most of the time. They represent 8% of the overall population and were held aside prior to running the models on the remaining 92% of respondents to create the other typology groups.
How we identified your typology group
Identifying which group is the best fit for you involves comparing the pattern of your answers to those from the typology groups defined using our national survey of 5,009 (see here for a description of how we created the typology groups).
For the 12 questions on the quiz used in defining the typology groups, we calculate how closely your response matches the average response to the question from respondents in each of the eight typology groups (bystanders are excluded from the quiz assignments). We then use those calculations to find the group that you are closest to, overall. (In more technical terms, we calculate the likelihood of you belonging to each of the eight groups and match you with the group that has the highest likelihood.)
Most people, but not all, are good fits for their group. Some patterns of responses to the value questions just do not match up well with any of the groups. The procedure will assign everyone to the group that fits them best, even if they are not a very good fit with any of the groups. And some people may actually be good fits for more than one group, since some of the groups are quite similar in many of their views.
If you feel you do not fit well with the group you are assigned to, that does not mean there is anything wrong with your responses. Your set of values may just be unique!

