The Pew Hispanic Center conducted a public opinion survey among people of Latino background or descent that was designed to ask questions specific to the topic of immigration. To fully represent the opinions of Latino people living in the United States, International Communications Research (ICR), an independent research firm headquartered in Media, Pa., conducted interviews with a statistically representative sample of Latinos in target regions of high Latino concentration so that they could be examined nationally. Furthermore, to increase the statistical power of various sub-groups, the design was stratified to include fewer Mexicans and greater numbers of non-Mexicans, as will be described below.
The study was conducted for The Pew Hispanic Center via telephone by ICR. Interviews were conducted from June 5 – July 3, 2006 among a nationally representative sample of 2,000 Latino respondents ages 18 and older. Of those respondents, 569 were native born (including Puerto Rico) and 1,429 were foreign born (excluding Puerto Rico). The margin of error for total respondents is +/-3.80 at the 95% confidence level. The margin of error for native-born respondents is +/-6.55 at the 95% confidence level. The margin of error for foreign-born respondents is +/-4.35 at the 95% confidence level.
For this survey, ICR maintained a staff of Spanish-speaking interviewers who, when contacting a household, were able to offer respondents the option of completing the survey in Spanish or English. A total of 468 respondents were surveyed in English, and 1,560 respondents were interviewed in Spanish (16 were surveyed in both languages).
Eligible Respondent
The survey was administered to any person ages 18 and older who is of Latino origin or descent, though some screening was necessary to interview fewer Mexicans and Central Americans (as described below).
Field Period
The field period for this study was June 5 – July 3, 2006. The interviewing was conducted by ICR. All interviews were conducted using the Computer Assisted Telephone Interviewing system. The CATI system ensured that questions followed logical skip patterns and that the listed attributes automatically rotated, eliminating “question position” bias.
Sampling Methodology
A stratified sample via the Optimal Sample Allocation sampling technique was used for the survey. By utilizing a stratified sample, one sample source was used to complete all interviews. This technique provides a highly accurate sampling frame. In this case, we examined a list of all telephone exchanges within a target area (national, by state, etc.) and listed them based on concentration of Latino households and specific Latino heritage. We then divided these exchanges into various groups, or strata.
Consequently, we used a disproportionate stratified RDD sample of Latino households. The primary stratification variables are the estimates of Latino household incidence and heritage in each NPA-NXX (area code and exchange) as provided by the GENESYS System – these estimates are derived from Claritas and are updated at the NXX level with each quarterly GENESYS database update. The basic procedure was to rank all NPA-NXXs in the United States by the incidence of Latino households and their ethnicity. This produced strata that were called Mexican, Puerto Rican, Cuban, Dominican, Central American, South American, High Latino, Medium Latino, and Low Latino. These strata were then run against InfoUSA and other listed databases, and then scrubbed against known Latino surnames. Any “hits” were subdivided into ‘surname’ strata, with all other sample being put into “RDD” strata. Overall, the study employed 18 strata, 9 (Mexican, Puerto Rican, etc.) x 2 (surname/RDD). There are two important aspects of this plan worth noting. First, the existence of surname strata does not mean this was a surname sample design. The sample is RDD, only telephone numbers were then divided by whether they were found to be associated with or without a Latino surname. This was done simply to increase the number of strata (thereby increasing the control we have to meet ethnic targets) and to ease administration (allowing for more effective assignment of interviewers and labor hours). Second, just because a stratum is called, for example, “Mexican,” did not mean Mexicans were the only respondents we interviewed in that stratum. Rather, we accepted any Hispanic as valid for the study, in every strata. The only exception to this was Mexicans, where even in this design, whose goal was in part of lower the overall number of Mexican interviews, we still had to exclude every third Mexican household we encountered.
For purposes of estimation, we employed an optimal allocation scheme. This “textbook” approach allocates interviews to a stratum proportionate to the number of Latino HH but inversely proportionate to the square root of the relative cost, the relative cost in this situation being a simple function of the incidence. As such, the number of completed interviews increases as you move from a lower incidence strata to a higher incidence strata. Again, this is a known, formulaic approach to allocation that provides a starting point for discussions of sample allocation and associated costs. We have also provided estimates of the “effective sample size” associated with the resultant disproportionate allocation.
Sample generation within each defined stratum utilized a strict epsem sampling procedure, providing equal probability of selection to every telephone number. The overall sampling design was as follows:

Overall, the design ended up with the following completes by ethnicity:
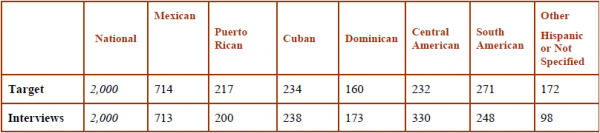
Approximately halfway through the study it was noted that we were going to get a disproportionate number of Central Americans in comparison to “Other” Hispanics. As such we promptly lowered the targets for the Central American strata. However, the High, Medium and Low strata also attained a significant number of Central Americans, and as such increasing the quota in those strata would not solve the problem. ICR then began to exclude Central Americans from the High, Medium and Low strata. That minimized the imbalance, though was not able at that point to completely solve it. Overall, however, the sample plan worked as designed, attaining an accurate number of Hispanics by heritage.
Weighting and Estimation
Weighting and estimation was performed independently within the strata. The first phase involved the adjustment of the actual final sample sizes to proportionality. Within strata, the population totals were determined from the 2006 Claritas data. An initial weight, or proportionality factor, was then computed for each strata.
Then, interviews were balanced using a sample balancing routine controlling for age within sex, gender, education, heritage, and foreign/native born status, using 2005 CPS data. The balancing process also controlled to produce weights scaled to the earlier determined proportionality weights.
Response Rate
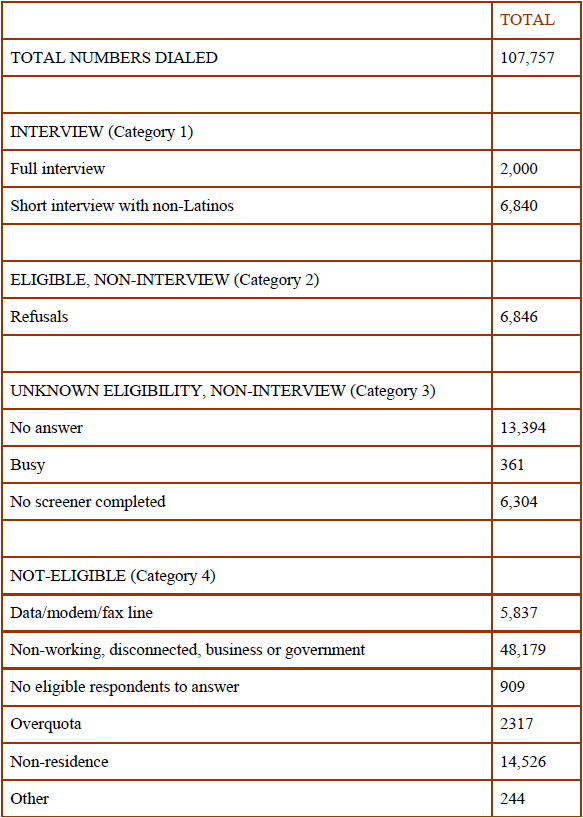
The overall response rate for this study was calculated to be 45.9% using AAPOR’s RR3 formula. Following is a full disposition of the sample selected for this survey: