News outlet selection
The study was based on American news outlets whose websites:
- Have a monthly average of more than 20 million unique visitors from July-September of 2018, according to Comscore’s data (Comscore Media Metrix Multi-platform, unique visitors, July-September 2018).
- Provide original reporting and news and information content for a general audience.
- Cover a variety of topics rather than specializing in a particular topic (such as weather, sports, politics, business or entertainment)
- Are based in the U.S.
- Focus at least in part on national issues (rather than focusing solely on local issues).
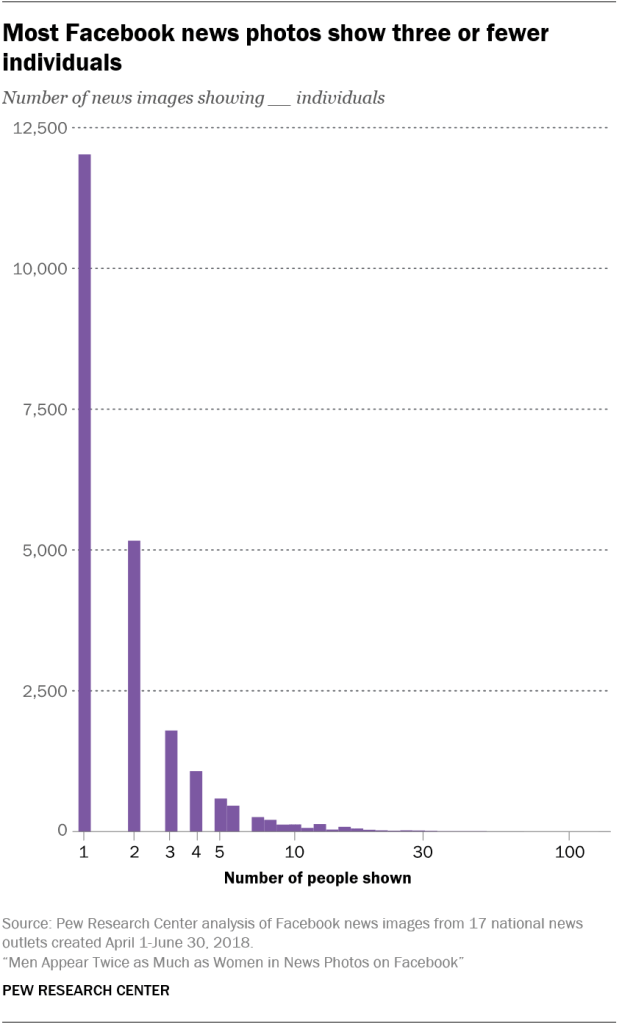
After applying these rules, researchers included the following outlets: ABC News, BuzzFeed News, CBS News, CNN, Fox News, HuffPost, NBC News, The New York Times, Newsweek, NPR, Time, U.S. News & World Report, USA Today, The Washington Post, Yahoo News, Vice and Vox.
Data collection
To create the dataset used for both analyses, researchers built a data pipeline to streamline image collection, facial recognition and extraction, and facial classification tasks. To ensure that a large number of images could be processed in a timely manner, the team set up a database and analysis environment on the Amazon Web Service (AWS) cloud, which enabled the use of graphics processing units (GPUs) for faster image processing.
Data collection took place in April, May and June of 2018. The information collected about each post includes the title, caption and a brief comment which appeared within the post.
Face detection
Researchers used the face detector from the Python library dlib to identify all faces in the image. The program identifies four coordinates of the face: top, right, bottom and left (in pixels). This system achieves 99.4% accuracy on the popular Labeled Faces in the Wild dataset. The research team cropped the faces from the images and stored them as separate files. A total of 44,056 photos were analyzed, 22,342 of which contained identifiable human faces.
Machine vision for gender classification
Researchers used a method called “transfer learning” to train a gender classifier rather than using machine vision methods developed by an outside vendor. In some commercial and noncommercial alternative classifiers, “multitask” learning methods are used to simultaneously perform face detection, landmark localization, pose estimation, gender recognition and other face analysis tasks. The research team’s classifier achieved high accuracy for the gender classification task while allowing the research team to monitor a variety of important performance metrics.
Gender classification model training
Recently, research has provided evidence of algorithmic bias in image classification systems from a variety of high profile vendors. This problem is believed to stem from imbalanced training data that often overrepresents white men. For this analysis, researchers decided to train a new gender classification model using a more balanced image training set. However, training an image classifier is a daunting task because collecting a large labeled dataset for training is very time and labor intensive and often is too computationally intensive to actually execute.
To avoid these challenges, the research team relied on a technique called “transfer learning,” which involves recycling large pretrained neural networks (a popular class of machine learning models) for more specific classification tasks. The key innovation of this technique is that lower layers of the pretrained neural networks often contain features that are useful across different image classification tasks. Researchers can reuse these pretrained lower layers and fine-tune the top layers for their specific application – in this case, the gender classification task.
The specific pretrained network researchers used is VGG16, implemented in the popular deep learning Python package Keras. The VGG network architecture was introduced by Karen Simonyan and Andrew Zisserman in their 2014 paper “Very Deep Convolutional Networks for Large Scale Image Recognition.” The model is trained using ImageNet, which has over 1.2 million images and 1,000 object categories. Other common pretrained models include ResNet and Inception. VGG16 contains 16 weight layers that include several convolution and fully connected layers. The VGG16 network has achieved a 90% top-5 accuracy in ImageNet classification.
Researchers began with the classic architecture of the VGG16 neural network as a base and then added one fully connected layer, one dropout layer and one output layer. The team conducted two rounds of training – one for the layers added for the gender classification task (the custom model), and subsequently one for the upper layers of the VGG base model.
Researchers froze the VGG base weights so that they could not be updated during the first round of training and restricted training during this phase to the custom layers. This choice reflects the fact that weights for the new layers are randomly initialized, so if the VGG weights are allowed to be updated it would destroy the information contained within them. After 20 epochs of training on just the custom model, the team unfroze four top layers of the VGG base and began a second round of training. For the second round of training, researchers implemented an early stopping function. Early stopping checks the progress of the model loss (or error rate) during training and halts training when validation loss value ceases to improve. This serves as both a timesaver and keeps the model from overfitting to the training data.
In order to prevent the model from overfitting to the training images, researchers randomly augmented each image during the training process. These random augmentations included rotations, shifting of the center of the image, zooming in/out, and shearing the image. As such, the model never saw the same image twice during training.
Selecting training images
Image classification systems, even those that draw on pretrained models, require a substantial amount of training and validation data. These systems also demand diverse training samples if they are to be accurate across demographic groups. Researchers took a variety of steps to ensure that the model was accurate when classifying the gender of people from diverse backgrounds.
First, the team located existing datasets used by researchers for image analysis. These include the “Labeled Faces in the Wild” (LFW) and “Bainbridge 10K U.S. Adult Faces” datasets. Second, the team downloaded images of Brazilian politicians from a site that hosts municipal-level election results. Brazil is a racially diverse country, and that is reflected in the demographic diversity in its politicians. Third, researchers created original lists of celebrities who belong to different minority groups and collected 100 images for each individual.
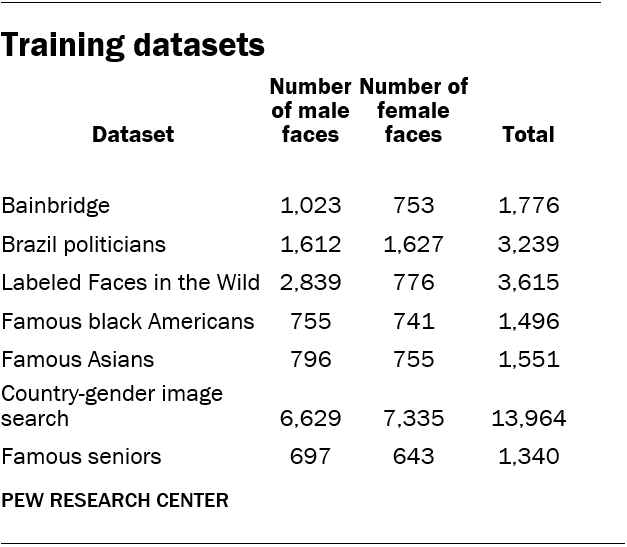
The list of minority celebrities focused on famous black and Asian individuals. The list of famous blacks includes 22 individuals: 11 men and 11 women. The list of famous Asians includes 30 individuals: 15 men and 15 women. Researchers then compiled a list of the most populous 100 countries and downloaded up to 100 images of men and women for each nation-gender combination, respectively (for example, “French man”). This choice helped ensure that the training data included images that feature people from a diverse set of countries, balancing out the overrepresentation of white people in the training dataset. Finally, researchers supplemented this list with a set of 21 celebrity seniors (11 men and 10 women) to help improve model accuracy on older individuals. This allowed researchers to easily build up a demographically diverse dataset of faces with known gender and racial profiles.
Some images feature multiple people. To ensure that the images were directly relevant, a member of the research team reviewed each face in the training datasets manually and removed irrelevant or erroneous faces (e.g., men in images with women). Researchers also removed images that were too blurry, too small and those where much of the face was obscured. In summary, the training data consist of 14,351 men and 12,630 women in images. The images belong to seven different datasets.
Gender classification model performance
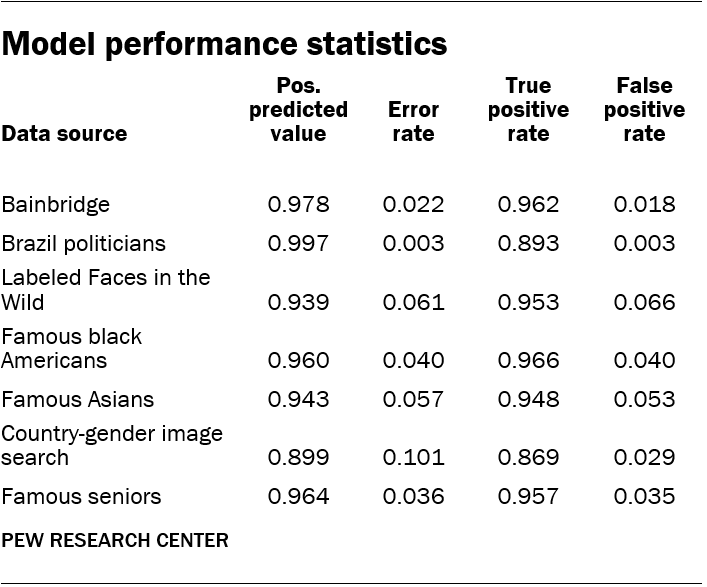
To evaluate whether the model was accurate, researchers applied it to a subset of the dataset equivalent to 20% of the image sources: a “held out” set which was not used for training purposes. The model achieved an overall accuracy of 95% on this set of validation data. The model was also accurate on particular subsets of the data, achieving 0.96 positive predictive value on the black celebrities subset, for example.
As a final validation exercise, researchers used an online labor market to create a hand coded random sample of 998 faces. This random subset of images overrepresented men — 629 of the images were coded as male by Mechanical Turk (MTurk) coders. Each face was coded by three online workers. For the 920 faces that had consensus across the three coders, the overall accuracy of this sample is 87%. Using the value 1 for “male” and 0 for “female,” the precision and recall of the model were 0.89 and 0.92, respectively, indicating that performance was balanced for both predictions.
Text classification and model performance
To determine whether news posts mentioned particular topics, researchers used a semi-supervised text classification algorithm. The topics were selected because they appeared in contemporaneous Pew Research Center surveys of U.S. adults either as among the most important problems facing the nation (health care, the economy and immigration) or as topics that individuals seek news about (sports and entertainment). Researchers developed a list of keywords related to each topic as “seed words” that initially classified posts as related to each of the topics or not. To narrow down the possible keywords for the entertainment category, researchers operationalized the concept as news mentioning TV, music or movies.
These initial positive cases were used as a training data set, which the researchers then used to fit a support vector machines (SVM) model. The SVM model detects words that co-occur with the “seed words” and uses those additional words to predict which posts were likely to be related to the topics of interest. The model also avoids the “seed words” associated with the other topics. The seed words of other topics help the model determine the negative cases. For example, when applying the model for sports, a post might use a seemingly relevant term like “winner” but also use terms associated with the economy like “trade war.” In such a case, the model is especially unlikely to classify the post as mentioning sports.
To prepare the data needed to train the model, researchers preprocessed the text by removing stop words. These words include commonly used English words such as “and,” “the,” or “of” that do not provide much information about the content of the text. Researchers then used the TfidfVectorizer in the sklearn python library to convert the text to tokens, including phrases that were one, two or three words long. The model was then applied to the full dataset, resulting in a prediction about whether every post mentioned one of the topics or not.
To validate this approach, researchers selected 1,100 posts for human coding. Since the prevalence of the posts that actually discuss each of the five topics was low, researchers used oversampling – based on model-based estimates – to increase the representation of positive cases in the validation sample. Specifically, researchers randomly selected approximately half of the posts that were tagged as positive by the SVM model, and the other half was tagged as negative. After removing duplicate posts, researchers classified 1,061 posts, determining whether they mentioned any of the five topics of interest. Interrater reliability statistics are weighted to reflect the oversampling process.
Two in-house coders classified the same subset of posts (406) to ensure that humans could reasonably agree on whether or not a post mentioned each issue. After conducting the content coding, researchers resolved disagreements and created a consolidated set of human decisions to compare the model against. The vast majority of posts were coded as mentioning to a single topic, 55 posts in total (0.1%) were coded as mentioning to multiple topics.
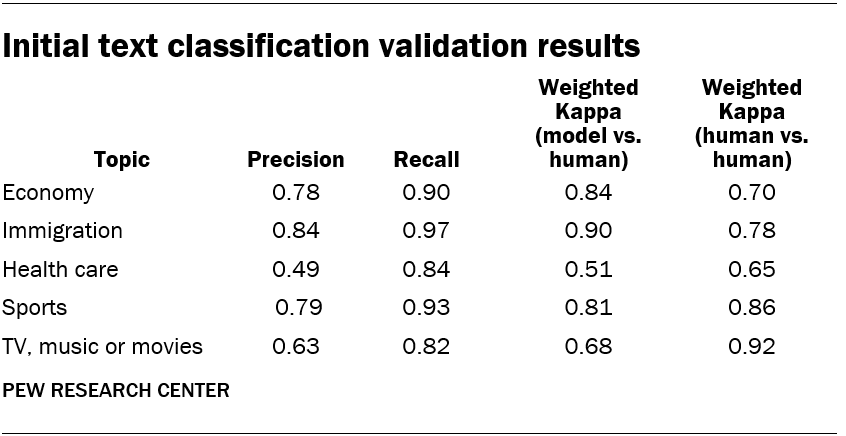
The performance of the model and the human coders’ agreement with each other is described in the table above. The model can be assessed via precision, recall, and weighted kappa, each of which compares how well the model’s decisions correspond with those of the human coders. The final column shows the weighted kappa for the subset of posts coded by two coders, comparing their decisions against each other.
Researchers found that the health care topic had low precision, suggesting that many posts that the model identified as mentioning the topic did not in fact mention it. A manual review of posts revealed that the model incorrectly classified posts that mentioned personal health and wellness as mentioning health care, while the coders were focused on health care policy or general health care issues. Since the words associated with health care policy were so similar to those associated with personal health and wellness, researchers decided to exclude this topic from further analysis.
The precision value for TV, music or movies was also low, but it was clear in this case that false positives were decreasing model performance, due to both the “seed” keywords associated with the topic and the penalty that the model applied to mislabeled posts. In response, researchers revised the keyword list and also adjusted the model parameter that controls the size of the penalty assigned to mislabeled posts. If that model parameter is smaller, the model will achieve better separation between the positive and negative posts. So researchers lowered the parameter from 1 to 0.05.
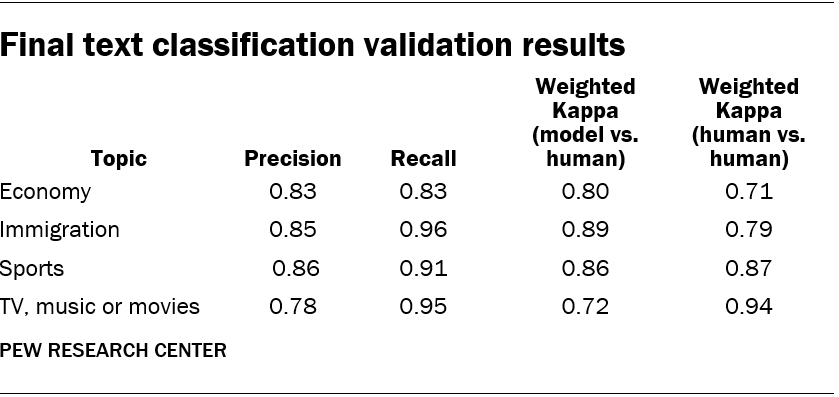
Since changing the model risks overfitting to the data, researchers separately drew a new sample of 100 posts (50 positive and 50 negative) to conduct model validation. Two in-house coders classified these posts. After reevaluating the models, researchers arrived at the following performance statistics.6
Performance statistics for the topic including TV, music or movies was substantially better in this round of validation: Both precision and recall increased. The model performance of the other topics also changed slightly due to the fact that seed words for one topic identify negative cases for other topics; since the keyword list for TV, music or movies changed in this round, it also affected the results of the other topics.
Precision and recall are statistics used to quantify the performance of statistical models making predictions. Low values for precision signify that the model is making a positive prediction about a post or image when in fact the prediction should be negative. Low values of recall signify that the model is systematically missing positive cases that ought to be labeled as such.
Cohen’s Kappa is a statistic used to assess interrater reliability. It ranges from 0 (meaning that two separate sets of decisions are only related to each other according to chance) to 1 (meaning that two separate decisions perfectly agree, even adjusting for chance agreement).
Deep learning is a class of machine learning models that is inspired by how biological nervous systems process information. These kinds of models include multiple layers of information that help make predictions. In this report, researchers used deep learning models to predict whether human faces belonged to men or women.
Support vector machines refers to a common machine learning algorithm. The algorithm uses the decision of multiple models and aims to achieve clear separation between classes of data, or predictions. In this case, researchers used support vector machines to classify whether or not posts mentioned particular news topics.






