The Religious Landscape Study (RLS), on which this report is based, is a national cross-sectional survey conducted for Pew Research Center by NORC at the University of Chicago.
It was conducted in English and Spanish from July 17, 2023, to March 4, 2024, among a nationally representative sample of 36,908 U.S. adults.
A geographically stratified address-based sample was drawn from the United States Postal Service’s Computerized Delivery Sequence File (CDS).
The survey was designed to produce reliable state and national estimates of the U.S. adult population. In geographies with a sufficiently large number of completed interviews, metropolitan statistical area (MSA) estimates are also available.
A total of 205,100 sampled addresses were mailed survey invitations. Respondents were given a choice to complete the survey online, by mail, or by calling a toll-free number and completing the survey over the phone with an interviewer. Of the 36,908 U.S. adults who completed the survey, 25,250 did so online, 10,733 did so by mail, and 925 did so by phone.
After accounting for the complex sample design and loss of precision due to weighting, the national margin of sampling error for these respondents is plus or minus 0.8 percentage points at the 95% level of confidence.
The research plan for this project was submitted to NORC’s institutional review board (IRB), which is an independent committee of experts that specializes in helping to protect the rights of research participants. This research was declared exempt under category 2 of IRB code (approval #: FWA 00000142).
Sample design
The survey has a complex sample design constructed to ensure reliable estimates for the nation as a whole, for each state (and the District of Columbia), and for some of the largest MSAs.
The sample frame of the 2023-24 RLS is an address-based sample (ABS) comprised of addresses from the USPS CDS file. It is maintained by Vericast and is updated monthly. All residential addresses on the ABS frame were geocoded and assigned to one of 93 strata.
Addresses were initially stratified by state and the District of Columbia. When sample sizes were large enough, states were further partitioned into target MSA strata and non-MSA state strata. For example, the entire state of Connecticut is comprised of one stratum, but five strata cover California (Los Angeles-Long Beach-Anaheim; San Francisco-Oakland-Berkeley; Riverside-San Bernardino-Ontario; San Diego-Chula Vista-Carlsbad; and all other addresses within California). Strata were defined at the county level and respected state boundaries.
The sample was proportionally allocated but adjusted to account for differential nonresponse and to ensure that a minimum of 300 people in each state completed the survey. Additionally, allocation was optimally adjusted within states so that the survey obtained at least 250 completed surveys from respondents in at least 32 large MSAs while balancing overall design effects due to unequal probability of household selection.94 Addresses were randomly selected within each stratum.
Once an address was sampled, an invitation was mailed to the address. The invitation asked the adult in the household with the next birthday to complete the survey.
Sampled addresses were contacted in two batches. Addresses in the first batch were first contacted on July 14, 2023, while those in the second batch were first contacted on Oct. 27, 2023. Response rates from the first batch informed the size of the second batch, to ensure the study reached the targeted number of completed interviews.
Data collection
The survey used a sequential mixed-mode protocol in which sampled households were first invited to respond online and then, if they did not respond online, mailed a paper version of the questionnaire. A toll-free phone number was included in all contact attempts, and individuals were told they could call it to complete the survey over the phone with an interviewer.
The first mailing included a letter introducing the survey and providing the information needed to respond online or by phone (website URL, unique access PIN, and phone number). A pre-incentive of $2 was included in the mailing and could be seen through a windowed envelope. The letter promised an additional $10 once the survey was complete.95 The invitation was generic; it asked respondents to “answer some questions in a short online survey” and said that “the survey asks about a variety of topics that affect you and your community.” We intentionally avoided telling respondents in the letter that the survey focused heavily on religion, because we wanted to minimize the risk of biasing the survey’s results by appealing disproportionately to people who are interested in religion. Materials were sent in both English and Spanish to 15% of addresses, and in English only to 85% of addresses.
One week after the first mailing, NORC sent a postcard reminder to all sampled individuals, followed a week later by a reminder letter to nonrespondents.
After that, a 16-page paper version of the survey, postage-paid return envelope, cover letter and another $2 prepaid incentive were mailed to nonrespondents. The timing and postage method for this mailing varied. Addresses sampled as part of the first batch were mailed these materials 10 days after the reminder letter was sent out, whereas addresses in the second batch were mailed two months after the reminder letter. The second batch delay was designed to avoid sending mail over the holiday season from Thanksgiving through New Year’s Day. Mailings to the first batch of addresses and 75% of the second batch were sent using first class mail. The remaining 25% of addresses in the second batch were sent via UPS Mail Innovations. This change was made to increase the response rate while respecting budget limitations.
One to two weeks later, a reminder postcard followed the paper surveys.
A sample of 60% of nonresponding addresses in the first sample batch also received a second paper version of the survey approximately one month after the first; this sample was drawn proportional to the household’s response propensity estimated through predictive modeling using big data classifiers. This mailing included a copy of the paper questionnaire, a cover letter, postage-paid envelope, and an additional prepaid incentive. The hardest-to-reach nonrespondents received a $5 incentive while others received a $2 incentive. This final mailing was not sent to the second sample batch due to budget and time constraints.
In addition to the above protocol, a methodological contact experiment was built into the 2023-24 RLS. When available, cellphone numbers were appended to nonresponding addresses and a random subsample of these numbers received a text message. The text message contained either a link to the web survey or gave recipients both the web link and the toll-free telephone number for completing the survey via phone. In the first sample batch, text messages were sent following the final mailing. In the second sample batch, they were sent following the reminder web letter and before the first paper questionnaire was sent.
Languages
English materials were mailed to all sampled addresses while Spanish materials were also included in mailings to the 15% of addressees identified as most likely to have a Spanish speaker. Addresses that were likely to be home to Spanish-speaking people were identified using a combination of vendor-provided commercial flags, Bayesian Improved Surname and Geocoding (BISG), and isolated Spanish language Census tracts.
For the web survey, the landing page was displayed in English initially but allowed respondents to toggle between English and Spanish. Respondents who called in to complete the survey over the phone were routed to an English or bilingual interviewer as appropriate. Paper questionnaires in both languages were sent to households flagged to receive bilingual materials.
Weighting and variance estimation
Household-level weighting
The first step in weighting was to create a base weight for each sampled mailing address, to account for its probability of selection into the sample. The base weight for mailing address k is called BWk and is defined as the inverse of its probability of selection. The addresses had a probability of selection based on the stratum from which they were sampled.
Each sampled mailing address was assigned to one of four categories according to its final screener disposition. The categories were 1) household with a completed interview, 2) household with an incomplete interview, 3) ineligible (i.e., not a household; these were primarily postmaster returns), and 4) addresses for which status was unknown (addresses that were not identified as undeliverable by the post office but from which no survey response was received).
The next step in the weighting process was to adjust the base weight to account for eligibility and nonresponse within each stratum. The proportion of ineligible households in each stratum was calculated under the assumption that all sampled households with unknown eligibility (category 4) were, in-fact, eligible. The proportion of ineligible households was then used to estimate the total number of eligible households in each stratum on the sampling frame. The base weights for responding households in each stratum (category 1) were then scaled so that their sum was equal to these estimated totals.
Person-level weights for national and state-level analysis
An initial adult base weight was calculated for the cases with a completed interview as the product of the truncated number of adults in the household (max value of 3) multiplied by the household weight. This adjustment accounted for selecting one adult in each household.
Next, an adaptive mode adjustment factor was applied to the adult base weight so that the relative weights for respondents who completed the survey in an offline mode (PAPI or CATI) were increased by a factor of two.

The final step in the adult weighting was to calibrate the adult weights for respondents who completed the survey, so that the calibrated weights (i.e., the estimated number of adults) aligned with benchmarks for noninstitutionalized U.S. adults (refer to the benchmarks listed in the accompanying table). For some raking dimensions that include the cross-classification of demographic variables within states (State x Race/Ethnicity, State x Gender x Education, and State x Age x Education), cells with fewer than 30 completed interviews were collapsed with neighboring cells to prevent the creation of extreme weight values and to ensure the convergence of the raking process. These weights were then trimmed separately within each stratum at the 1st and 99th percentiles, to reduce the loss in precision stemming from variance in the weights.
Person-level weights for the analysis of MSAs
An additional set of weights was created for the purpose of producing estimates for the 34 MSAs in which there were at least 250 completed interviews.96 To create this weight, the person-level weight for respondents living in these MSAs was further calibrated on the following dimensions within each MSA:
- Race/Ethnicity
- Age
- Gender
- Education
- Gender x Age
- Gender x Education
- Age x Education
Because MSA is not available on the American Community Survey 1-Year Public Use Microdata Sample, weighting benchmarks were estimated by allocating each case’s weight to one or more MSAs, according to the Public Use Microdata Area (PUMA) in which they live. This allocation was performed using a crosswalk from the Missouri Census Data Center’s Geocorr 2022 that contained the share of each PUMA’s population residing in every MSA as of the 2020 decennial census.
For some raking dimensions (Race/Ethnicity, Gender x Education, and Age x Education), cells with fewer than 25 completed interviews were collapsed with neighboring cells to prevent the creation of extreme weight values and to ensure the convergence of the raking process. In a final step, the MSA weight was trimmed separately within each MSA at the 1st and 99th percentiles.
Variance estimation
Bootstrap replication was used to facilitate variance estimation and conducting tests of statistical significance. Five hundred sets of replicates were created using the Rao-Wu rescaling bootstrap procedure as implemented in the survey package for the R statistical computing platform. The entire process for creating national weights was performed on the full sample and then separately repeated for each replicate. The result is a total of 501 separate weights for each respondent that have incorporated the variability from the complex sample design and weighting.97 Replicate weights were not created for the MSA weights.
The margins of sampling error reported in the tables here and on the RLS interactive website take into account the effect of weighting but they are not calculated using bootstrap replication. Margins of error are instead calculated using a formula based on the variability of respondent weights.98 This formula can be very conservative because it assumes that the weights are unrelated to the survey variables. Variance estimates that use the bootstrap replicates will generally show a greater level of precision because they are able to account for correlations between survey variables and the weights.
Response rates
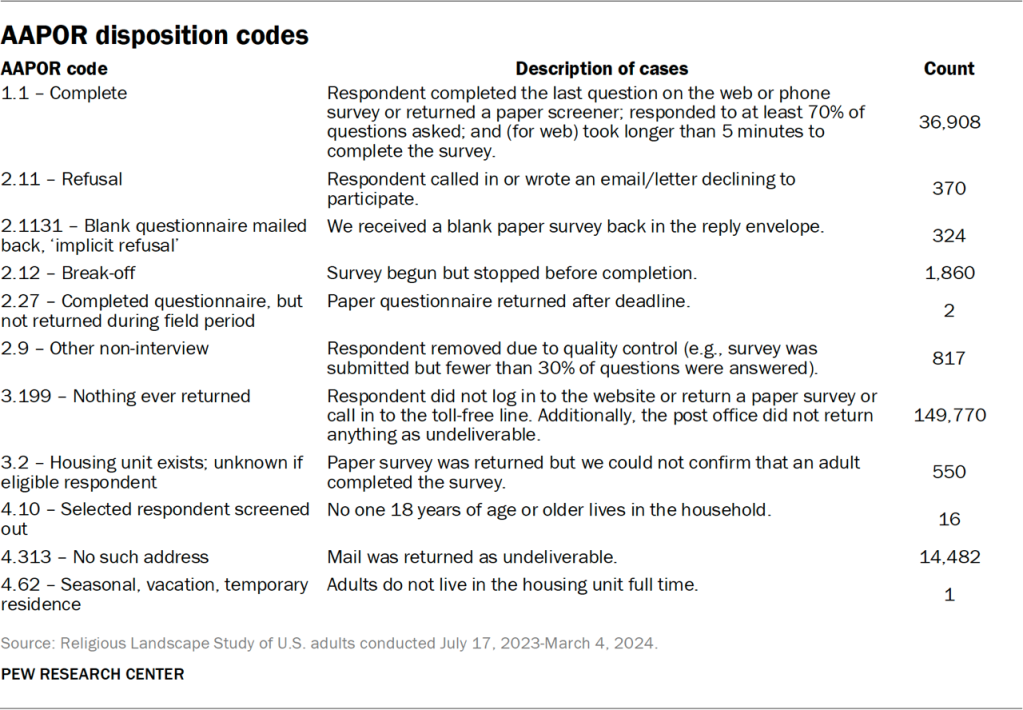
NORC assigned all sampled cases a result code and used these codes to compute response rates consistent with AAPOR definitions. The response rates are weighted by the base weight to account for the differential sampling in this survey. The AAPOR RR3 response rate was 20%.99
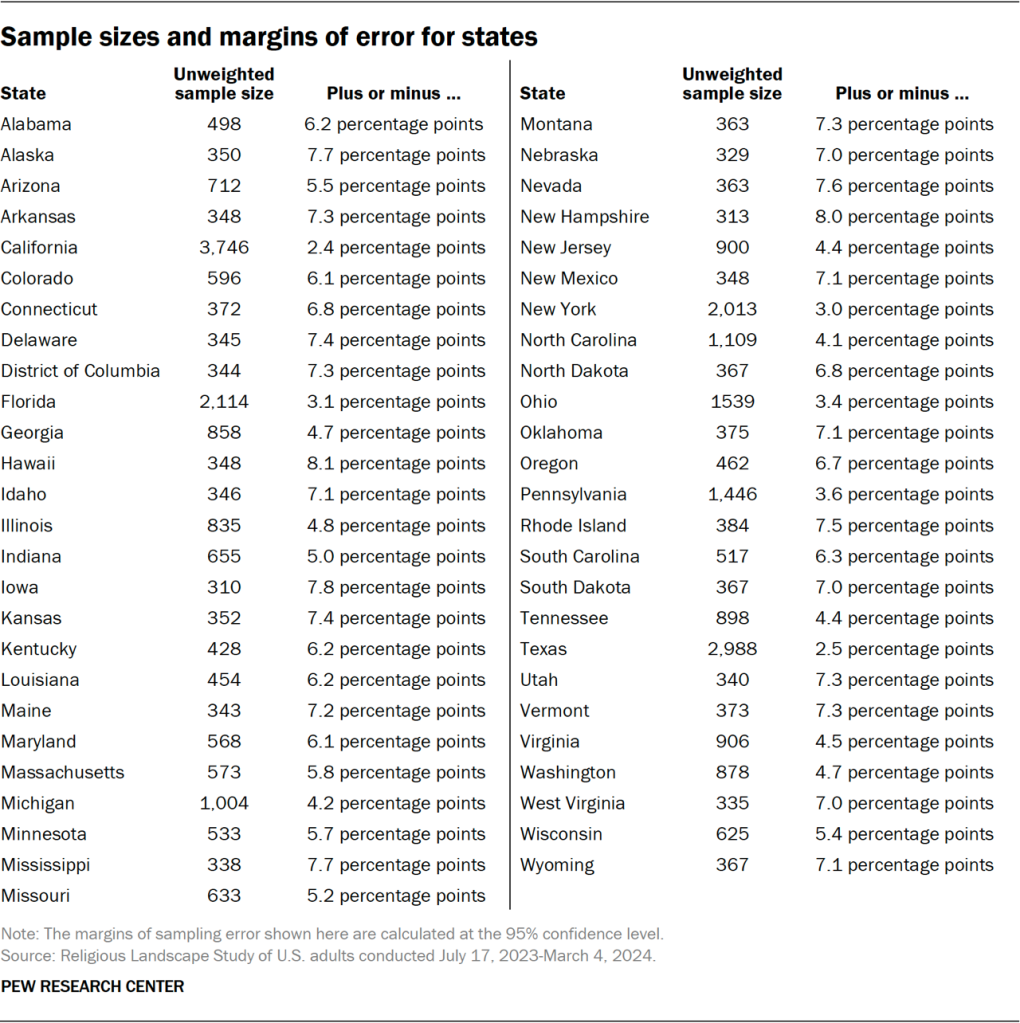
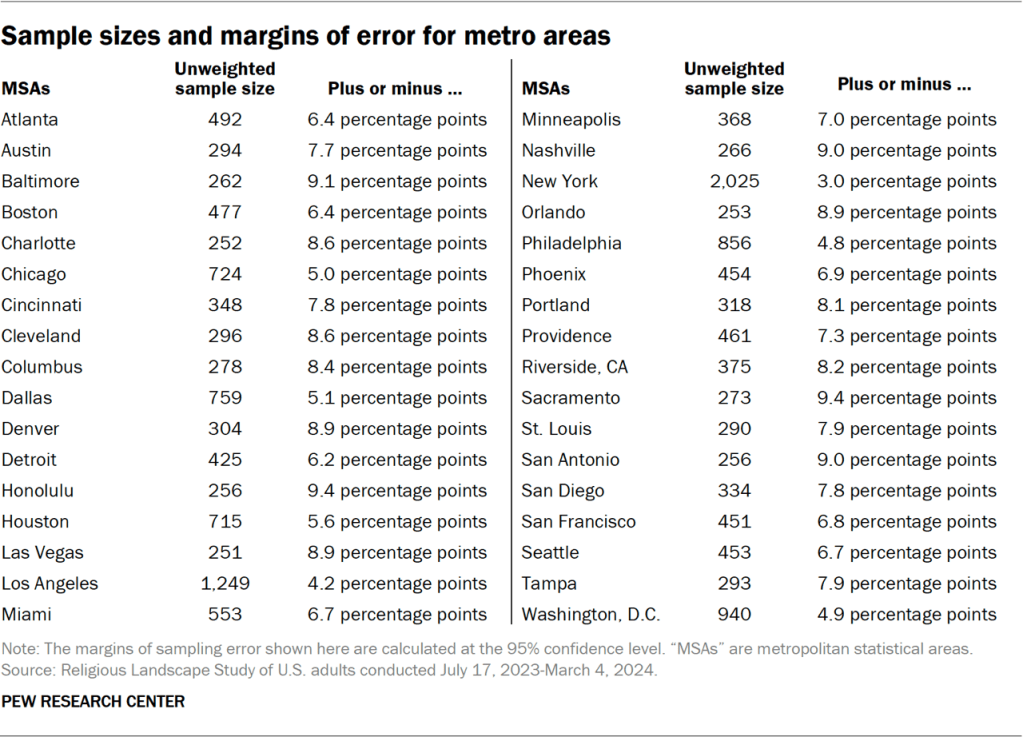
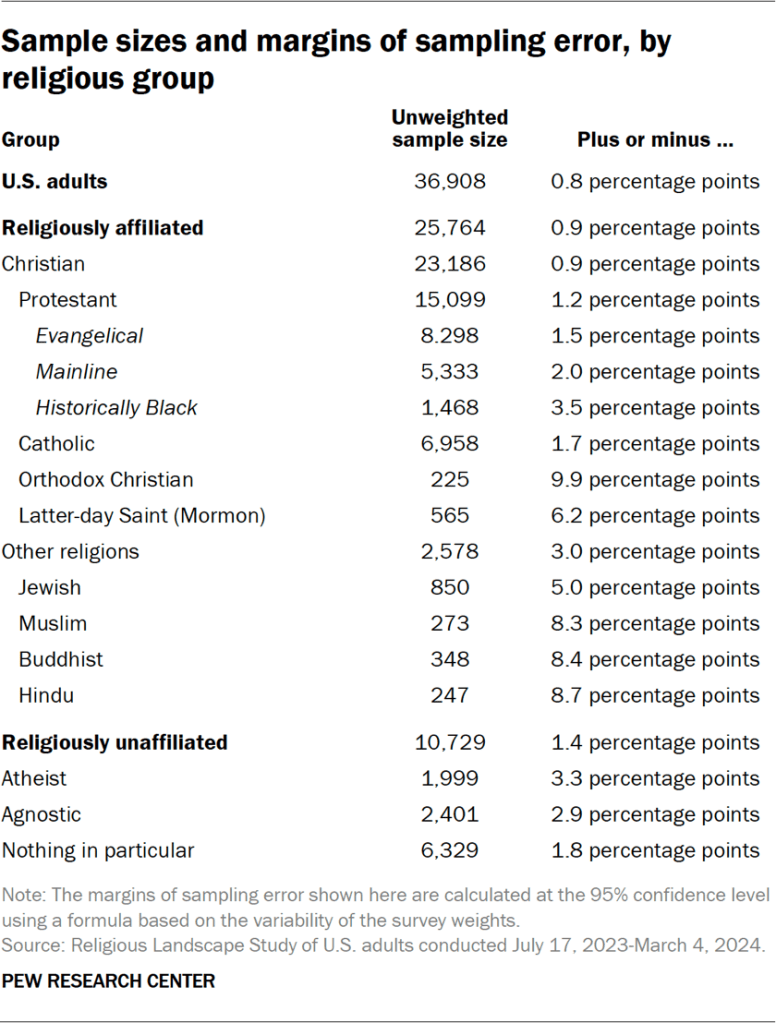
Sample sizes and margins of error for states and metro areas
The following tables show the unweighted sample sizes and the error attributable to sampling that would be expected at the 95% level of confidence for different groups in the survey.